


One of the major reasons to migrate to PD4ML v4 API is the support of the PDF/UA standard (Universal Accessibility).
PDF/UA standard is to let people with disabilities access PDF information in an efficient manner without assistance from others and be able to receive the same value from the content as others. PDF/UA does not add any new features to the PDF file format, but makes some aspects required which are optional in a regular PDF.
A lot of the requirements, like fonts embedding, were implicitly fulfilled even by older versions of PD4ML. But the major ones are covered only starting from PD4ML v4 – thanks to the new product architecture, which has been designed bearing in mind PDF/UA conformance.
PDF/UA requirements
- PDF/UA document must be tagged. It must include information regarding the nesting and relationship of different types of structure elements. It is probably the most annoying task to fulfill if you create PDF/UA using WYSIWYG tools from scratch or do manual PDF post-processing to achieve PDF/UA conformance. With PD4ML the task is trivial: a document structure comes from input HTML and can be perfectly automatically transformed to PDF tags.
- The document structure elements must have alternative descriptions. PD4ML uses for that a content specified by TITLE and ALT attributes of HTML tags. It is also a good idea to specify LANG attribute if the content not in English.
- PDF/UA document must be supplied with XML metadata. PD4ML generates it for you from known document/environment info. Make sure your input HTML document specifies
<title>,<meta name="description" content="document subject">,<meta name="author" content="author name">,<meta name="keywords" content="comma-delimited list of keywords">etc.
Enabling PDF/UA output
First you need to obtain PD4ML UA license with a license code. See the documentation.
Without the license code (or with a code of PD4ML license type, which does not enable PDF/UA feature) it still going to generate PDF/UA documents, but watermarked with “Evaluation” banner.
The next step is straightforward: invoke writePDF() method with PDFUA parameter.
PD4ML pd4ml = new PD4ML();
// important! PDF/UA requires TTF fonts to be embedded
// "arial,times,courier" is a comma-delimited list of font file name patterns to use
pd4ml.useTTF("c:/Windows/Fonts/", "arial,times,courier");
String html = "<html>\n" +
"<head>\n" +
"<title>PDF/UA Test</title>\n" +
"<meta name=\"description\" content=\"Document Subject\" />\n" +
"<meta name=\"author\" content=\"Max Mustermann\" />\n" +
"</head>\n" +
"<body lang=\"DE-de\">\n" +
"<div title=\"PDF/UA test content\">Prüfung auf PDF/UA-Konformität</div>\n" +
"</body>\n" +
"</html>";
ByteArrayInputStream bais =
new ByteArrayInputStream(html.getBytes());
// read and parse HTML
pd4ml.readHTML(bais);
File pdf = File.createTempFile("result", ".pdf");
FileOutputStream fos = new FileOutputStream(pdf);
// render and write the result as PDF
pd4ml.writePDF(fos, Constants.PDFUA);
// open the just-generated PDF with a default PDF viewer
Desktop.getDesktop().open(pdf);
If you run PD4ML as a standalone command line tool, you may force it to output PDF/UA with -outformat pdfua parameter.
In both cases do not forget to point PD4ML to a folder with indexed TTF/OTF fonts using pd4ml.useTTF(fontDir) API call or -ttf <ttf_fonts_dir> command line parameter.
PDF/UA validation
After PDF document is generated, it is a good idea to validate it for PDF/UA conformity. PD4ML did the best, but there are some aspects, that cannot be fully automated (e.g. providing of alternative descriptions).
There is a variety of PDF and PDF/UA validator tools. Our choice is free Free PDF Accessibility Checker (PAC 3)
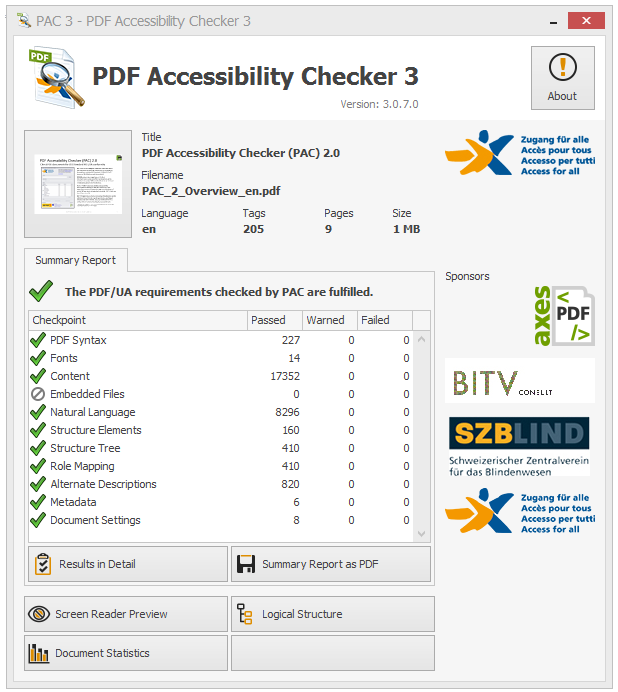
The PAC3 tool creates detailed validation reports, allows to browse the document structure to the problem elements and highlight them in the rendered content. However error messages can be not always clear. With some practice and collected validation experience their meaning becomes less confusing.
Alternatively you may use Preflight included to Adobe Acrobat Pro or diverse online validator applications (e.g. 3-HEIGHTS™ PDF VALIDATOR ONLINE TOOL). The tools are also great, but comparing to PAC3, they are mostly focused not on accessibility issues, but on technical/syntax aspects of PDF code (which should be not your, but our concern).
Most typical validation errors
-
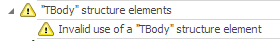 Despite the message, the real validation error reason is a missing of <thead> section in a table. Add missing <thead> section to suppress the message. PD4ML creates an implicit <thead> section if leading table rows contain <th> cells only.
Despite the message, the real validation error reason is a missing of <thead> section in a table. Add missing <thead> section to suppress the message. PD4ML creates an implicit <thead> section if leading table rows contain <th> cells only.
-
 The message is clear: in PDF/UA you are not allowed to nest, let’s say, <h4> heading to <h2>, which happens quite often in real life HTML documents.
The message is clear: in PDF/UA you are not allowed to nest, let’s say, <h4> heading to <h2>, which happens quite often in real life HTML documents.

