

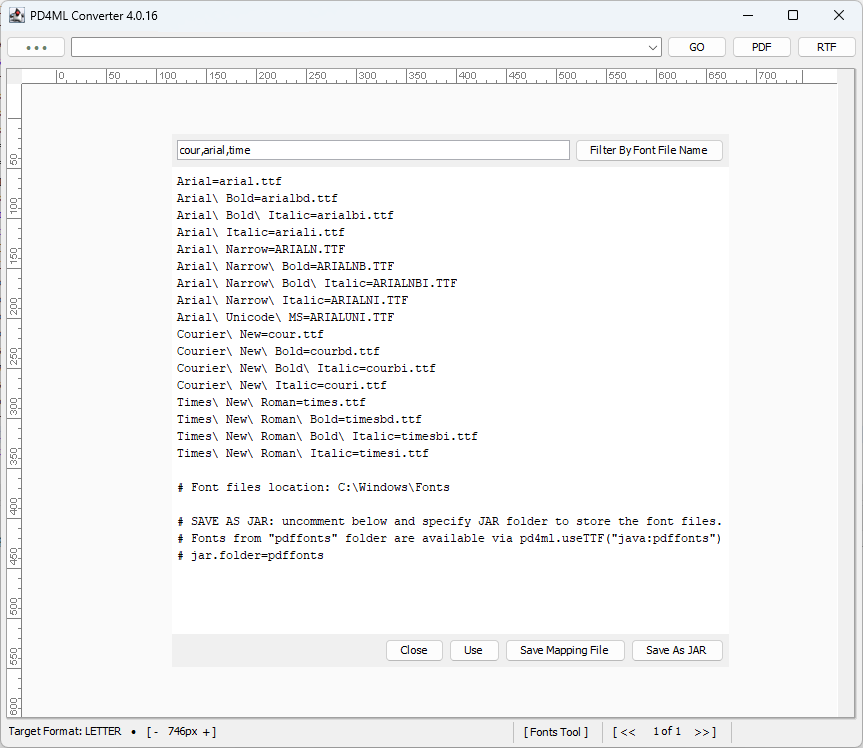
In version PD4ML v4.1.0 the product has been improved in the following areas:
- Security – AES-128 is used as the default encryption method
- PDF Standards conformance – allows you to specify the required PDF standard compliance. See: Compliance with PDF standards
- XML invoicing support – simplifies the creation of XML invoices that comply with the hybrid electronic invoicing standards. See: ZUGFeRD and Factur-X PDF Invoices generation
- Error policies – You can now specify how errors are handled: either ignore them or throw an exception at the caller level. Four policies can be defined: RELAXED (default; ignore all errors where possible), NORMAL (throw an exception on error), PEDANTIC (treat potential PDF/A and PDF/UA incompatibility as an error and throw an exception), and STRICT (throw an exception even on warnings, such as if the specified font cannot display some text and a fallback font is required).



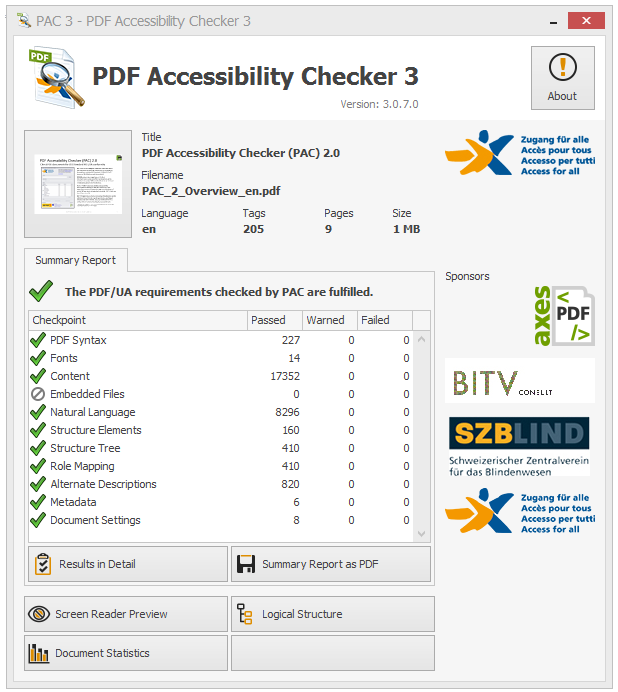
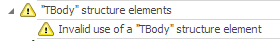 Despite the message, the real validation error reason is a missing of <thead> section in a table. Add missing <thead> section to suppress the message. PD4ML creates an implicit <thead> section if leading table rows contain <th> cells only.
Despite the message, the real validation error reason is a missing of <thead> section in a table. Add missing <thead> section to suppress the message. PD4ML creates an implicit <thead> section if leading table rows contain <th> cells only.
 The message is clear: in PDF/UA you are not allowed to nest, let’s say, <h4> heading to <h2>, which happens quite often in real life HTML documents.
The message is clear: in PDF/UA you are not allowed to nest, let’s say, <h4> heading to <h2>, which happens quite often in real life HTML documents.

