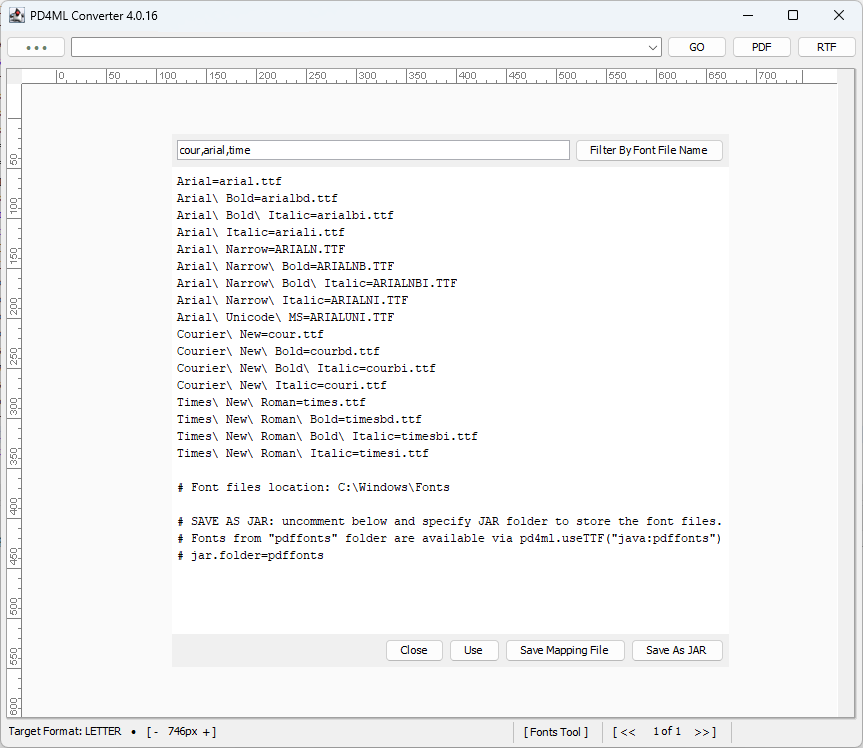
If the font in the generated PDF document does not match the font style defined in the HTML/CSS, first ensure that the font mapping is configured correctly.
Ideally, the font-family parameter (e.g., font-family: My Font) should correspond to the font key in the pd4fonts.properties file:
My\ Font=mybrandfont.ttf
(The space in the key name is escaped with a backslash.)
If the required font appears in the pd4fonts.properties file under a different name, for example:
My\ Brand\ Font=mybrandfont.ttf
you have two options:
- Modify the HTML or CSS to reference the registered font name:
font-family: My Brand Font;
- Add a new entry to the
pd4fonts.propertiesfile using the exact font name actually applied in the code:
My\ Brand\ Font=mybrandfont.ttf My\ Font=mybrandfont.ttf
If for any reason you are using the actual TTF filename directly in your HTML/CSS (
font-family: mybrandfont;), you can also add the corresponding key to the mapping file:My\ Brand\ Font=mybrandfont.ttf My\ Font=mybrandfont.ttf mybrandfont=mybrandfont.ttf
If the names of the fonts used in HTML are not known in advance, there is a high probability that font substitution fallback logic will be triggered. In such a case, the system will select any font belonging to the same typeface category (serif, sans-serif, or monospace) that is capable of displaying the specified text.
However, some fonts cannot be automatically assigned to a specific typeface category, so a bit of manual tweaking would help.
PD4ML supports a list of predefined placeholders for fallback font names, covering three font family categories (five for each):
customserif1 ... customserif5 customsans1 ... customsans5 custommono1 ... custommono5
Thus, you can add your font to a fallback list:
customsans1=mybrandfont.ttf
or even to all the lists at once if you prefer that this font be used in place of any missing ones
customserif1=mybrandfont.ttf customsans1=mybrandfont.ttf custommono1=mybrandfont.ttf